Data Visualization
Read CSV
Number of Ramen Review Based on Rating (Stars)
.png)
Number of Ramen Review Based on Brands
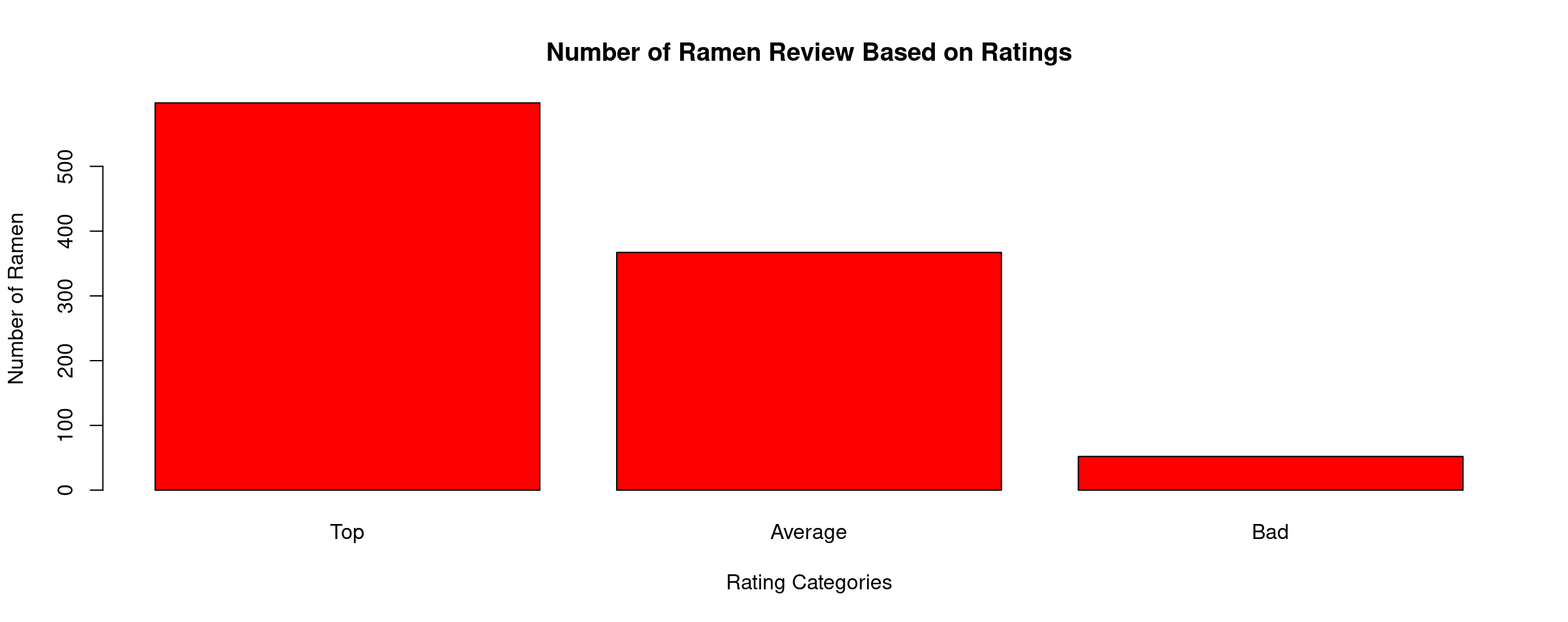
Number of Ramen Review Based on Ratings
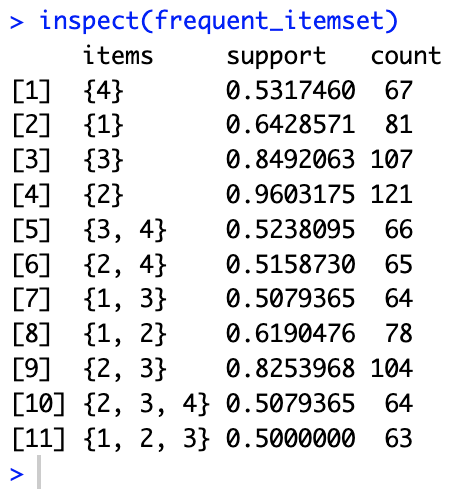
Frequent Pattern Analysis
Frequent pattern mining in data mining is the process of identifying patterns or associations within a dataset that occur frequently.
This is typically done by analyzing large datasets to find items or sets of items that appear together frequently.
Data Preprocessing
In this phase, we need to remove all country that is India,
remove all missing data,
and remove all duplicated data for the analysis.
Data Transformation
In this phase, we need to change the data, so it is suitable to be used in the apriori analysis.
Prepare the data in terms of the spicy level.
Data Mining
In this phase, we need to show frequent spicy levels using apriori algorithm with minimum support:
0.4 based on the data that have already pre-processed.
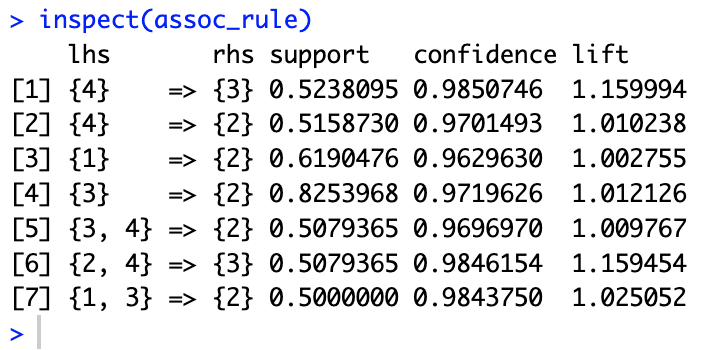
Then, we need to show the association rules using minimum confidence:
0.9 based on the frequent spicy levels that resulted from step above.
Apriori Algorithm
Apriori algorithm is used for finding frequent itemsets in a dataset for association rule mining.
We apply an iterative approach or level-wise search where k-frequent itemsets are used to find k+1 itemsets.
To improve the efficiency we used apriori property which helps by reducing the search space.
Association Rules
Association Rule is an unsupervised non-linear algorithm to uncover how the items are associated with each other.
In it, frequent Mining shows which items appear together in a transaction or relation.
There are three common ways to measure association: support, confidence, and lift.
References
https://www.geeksforgeeks.org/frequent-pattern-mining-in-data-mining/
https://www.geeksforgeeks.org/apriori-algorithm-in-r-programming/
https://www.geeksforgeeks.org/association-rule-mining-in-r-programming/